


Within the quickly evolving panorama of Generative AI (GenAI), information scientists and AI builders are continually searching for highly effective instruments to create revolutionary purposes utilizing Massive Language Fashions (LLMs). DataRobot has launched a collection of superior LLM analysis, testing, and evaluation metrics of their Playground, providing distinctive capabilities that set it aside from different platforms.
These metrics, together with faithfulness, correctness, citations, Rouge-1, value, and latency, present a complete and standardized strategy to validating the standard and efficiency of GenAI purposes. By leveraging these metrics, clients and AI builders can develop dependable, environment friendly, and high-value GenAI options with elevated confidence, accelerating their time-to-market and gaining a aggressive edge. On this weblog submit, we are going to take a deep dive into these metrics and discover how they might help you unlock the total potential of LLMs throughout the DataRobot platform.
Exploring Complete Analysis Metrics
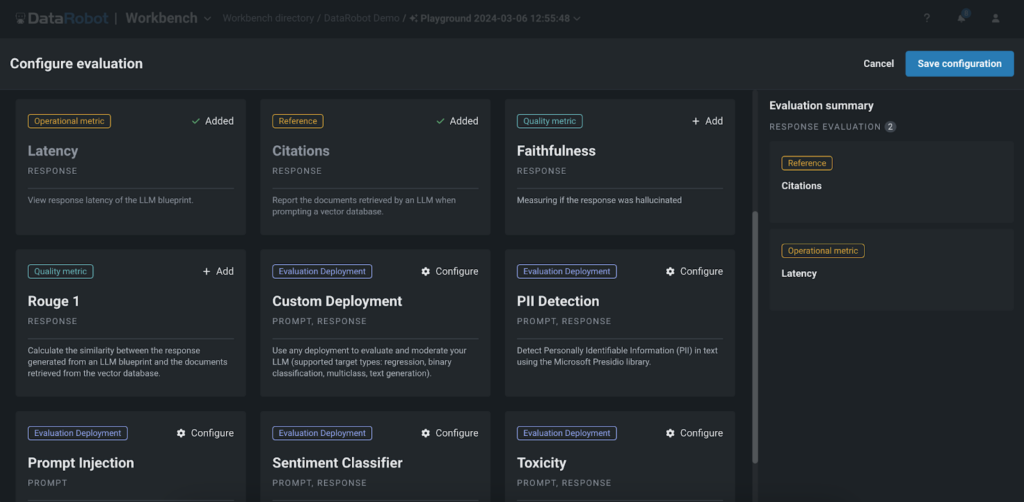
DataRobot’s Playground affords a complete set of analysis metrics that permit customers to benchmark, examine efficiency, and rank their Retrieval-Augmented Technology (RAG) experiments. These metrics embrace:
- Faithfulness: This metric evaluates how precisely the responses generated by the LLM mirror the info sourced from the vector databases, making certain the reliability of the knowledge.
- Correctness: By evaluating the generated responses with the bottom reality, the correctness metric assesses the accuracy of the LLM’s outputs. That is notably beneficial for purposes the place precision is vital, similar to in healthcare, finance, or authorized domains, enabling clients to belief the knowledge supplied by the GenAI utility.
- Citations: This metric tracks the paperwork retrieved by the LLM when prompting the vector database, offering insights into the sources used to generate the responses. It helps customers make sure that their utility is leveraging probably the most applicable sources, enhancing the relevance and credibility of the generated content material.The Playground’s guard fashions can help in verifying the standard and relevance of the citations utilized by the LLMs.
- Rouge-1: The Rouge-1 metric calculates the overlap of unigram (every phrase) between the generated response and the paperwork retrieved from the vector databases, permitting customers to judge the relevance of the generated content material.
- Price and Latency: We additionally present metrics to trace the associated fee and latency related to working the LLM, enabling customers to optimize their experiments for effectivity and cost-effectiveness. These metrics assist organizations discover the suitable steadiness between efficiency and finances constraints, making certain the feasibility of deploying GenAI purposes at scale.
- Guard fashions: Our platform permits customers to use guard fashions from the DataRobot Registry or customized fashions to evaluate LLM responses. Fashions like toxicity and PII detectors could be added to the playground to judge every LLM output. This permits straightforward testing of guard fashions on LLM responses earlier than deploying to manufacturing.
Environment friendly Experimentation
DataRobot’s Playground empowers clients and AI builders to experiment freely with totally different LLMs, chunking methods, embedding strategies, and prompting strategies. The evaluation metrics play an important position in serving to customers effectively navigate this experimentation course of. By offering a standardized set of analysis metrics, DataRobot allows customers to simply examine the efficiency of various LLM configurations and experiments. This enables clients and AI builders to make data-driven selections when choosing the right strategy for his or her particular use case, saving time and assets within the course of.
For instance, by experimenting with totally different chunking methods or embedding strategies, customers have been capable of considerably enhance the accuracy and relevance of their GenAI purposes in real-world eventualities. This stage of experimentation is essential for creating high-performing GenAI options tailor-made to particular business necessities.
Optimization and Consumer Suggestions
The evaluation metrics in Playground act as a beneficial instrument for evaluating the efficiency of GenAI purposes. By analyzing metrics similar to Rouge-1 or citations, clients and AI builders can determine areas the place their fashions could be improved, similar to enhancing the relevance of generated responses or making certain that the appliance is leveraging probably the most applicable sources from the vector databases. These metrics present a quantitative strategy to assessing the standard of the generated responses.
Along with the evaluation metrics, DataRobot’s Playground permits customers to offer direct suggestions on the generated responses by means of thumbs up/down rankings. This person suggestions is the first technique for making a fine-tuning dataset. Customers can assessment the responses generated by the LLM and vote on their high quality and relevance. The up-voted responses are then used to create a dataset for fine-tuning the GenAI utility, enabling it to be taught from the person’s preferences and generate extra correct and related responses sooner or later. Which means that customers can accumulate as a lot suggestions as wanted to create a complete fine-tuning dataset that displays real-world person preferences and necessities.
By combining the evaluation metrics and person suggestions, clients and AI builders could make data-driven selections to optimize their GenAI purposes. They will use the metrics to determine high-performing responses and embrace them within the fine-tuning dataset, making certain that the mannequin learns from the very best examples. This iterative technique of analysis, suggestions, and fine-tuning allows organizations to constantly enhance their GenAI purposes and ship high-quality, user-centric experiences.
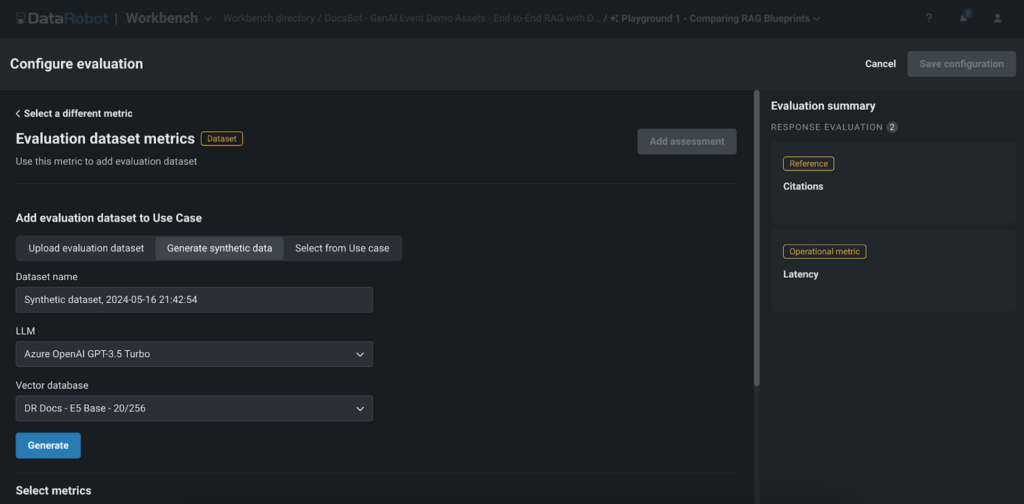
Artificial Information Technology for Speedy Analysis
One of many standout options of DataRobot’s Playground is the artificial information technology for prompt-and-answer analysis. This function permits customers to shortly and effortlessly create question-and-answer pairs primarily based on the person’s vector database, enabling them to totally consider the efficiency of their RAG experiments with out the necessity for guide information creation.
Artificial information technology affords a number of key advantages:
- Time-saving: Creating massive datasets manually could be time-consuming. DataRobot’s artificial information technology automates this course of, saving beneficial time and assets, and permitting clients and AI builders to quickly prototype and take a look at their GenAI purposes.
- Scalability: With the flexibility to generate hundreds of question-and-answer pairs, customers can totally take a look at their RAG experiments and guarantee robustness throughout a variety of eventualities. This complete testing strategy helps clients and AI builders ship high-quality purposes that meet the wants and expectations of their end-users.
- High quality evaluation: By evaluating the generated responses with the artificial information, customers can simply consider the standard and accuracy of their GenAI utility. This accelerates the time-to-value for his or her GenAI purposes, enabling organizations to convey their revolutionary options to market extra shortly and acquire a aggressive edge of their respective industries.
It’s necessary to think about that whereas artificial information supplies a fast and environment friendly strategy to consider GenAI purposes, it might not all the time seize the total complexity and nuances of real-world information. Subsequently, it’s essential to make use of artificial information together with actual person suggestions and different analysis strategies to make sure the robustness and effectiveness of the GenAI utility.
Conclusion
DataRobot’s superior LLM analysis, testing, and evaluation metrics in Playground present clients and AI builders with a strong toolset to create high-quality, dependable, and environment friendly GenAI purposes. By providing complete analysis metrics, environment friendly experimentation and optimization capabilities, person suggestions integration, and artificial information technology for fast analysis, DataRobot empowers customers to unlock the total potential of LLMs and drive significant outcomes.
With elevated confidence in mannequin efficiency, accelerated time-to-value, and the flexibility to fine-tune their purposes, clients and AI builders can deal with delivering revolutionary options that remedy real-world issues and create worth for his or her end-users. DataRobot’s Playground, with its superior evaluation metrics and distinctive options, is a game-changer within the GenAI panorama, enabling organizations to push the boundaries of what’s doable with Massive Language Fashions.
Don’t miss out on the chance to optimize your initiatives with probably the most superior LLM testing and analysis platform accessible. Go to DataRobot’s Playground now and start your journey in direction of constructing superior GenAI purposes that really stand out within the aggressive AI panorama.
Concerning the writer

Nathaniel Daly is a Senior Product Supervisor at DataRobot specializing in AutoML and time sequence merchandise. He’s centered on bringing advances in information science to customers such that they will leverage this worth to resolve actual world enterprise issues. He holds a level in Arithmetic from College of California, Berkeley.